
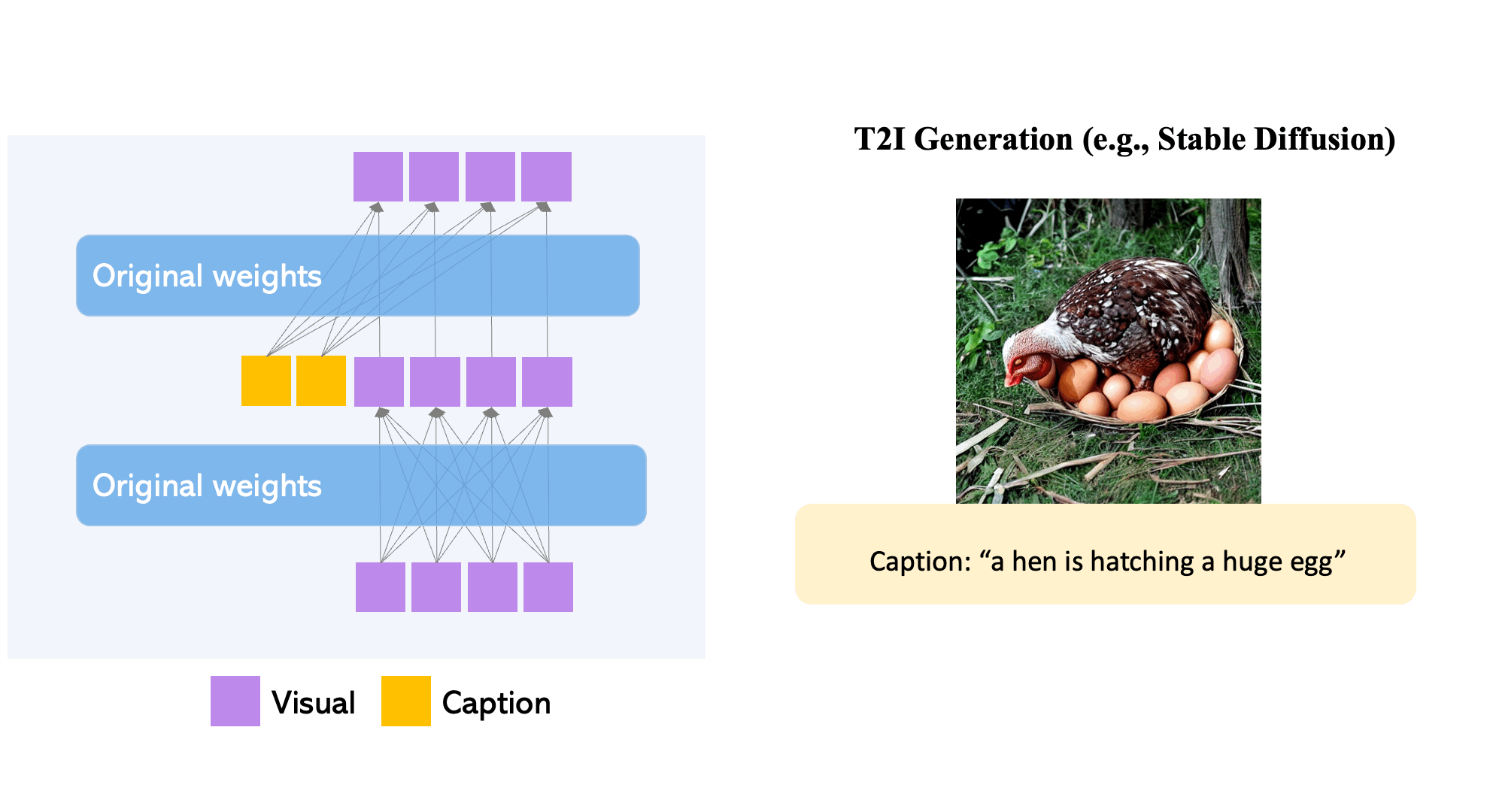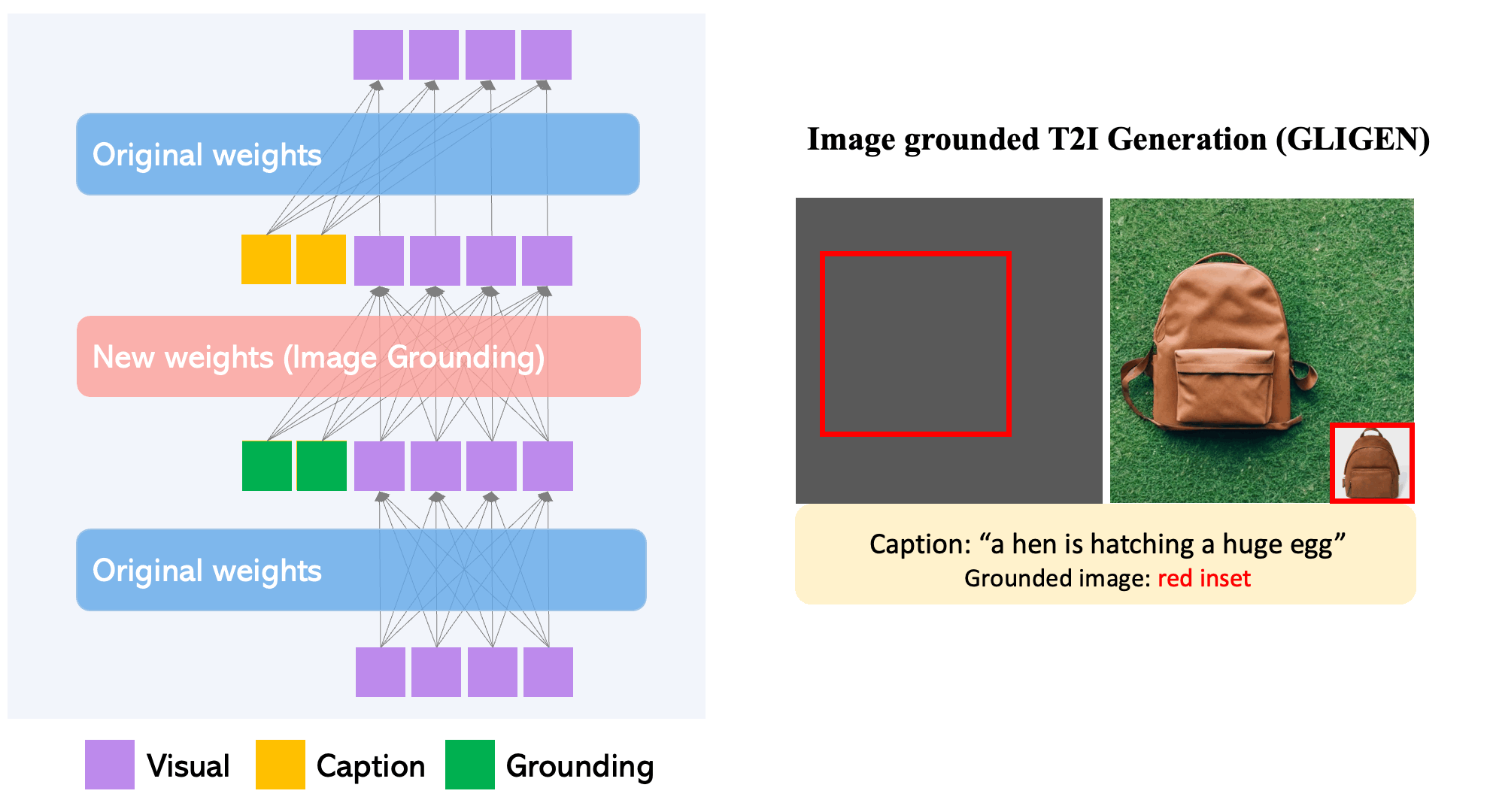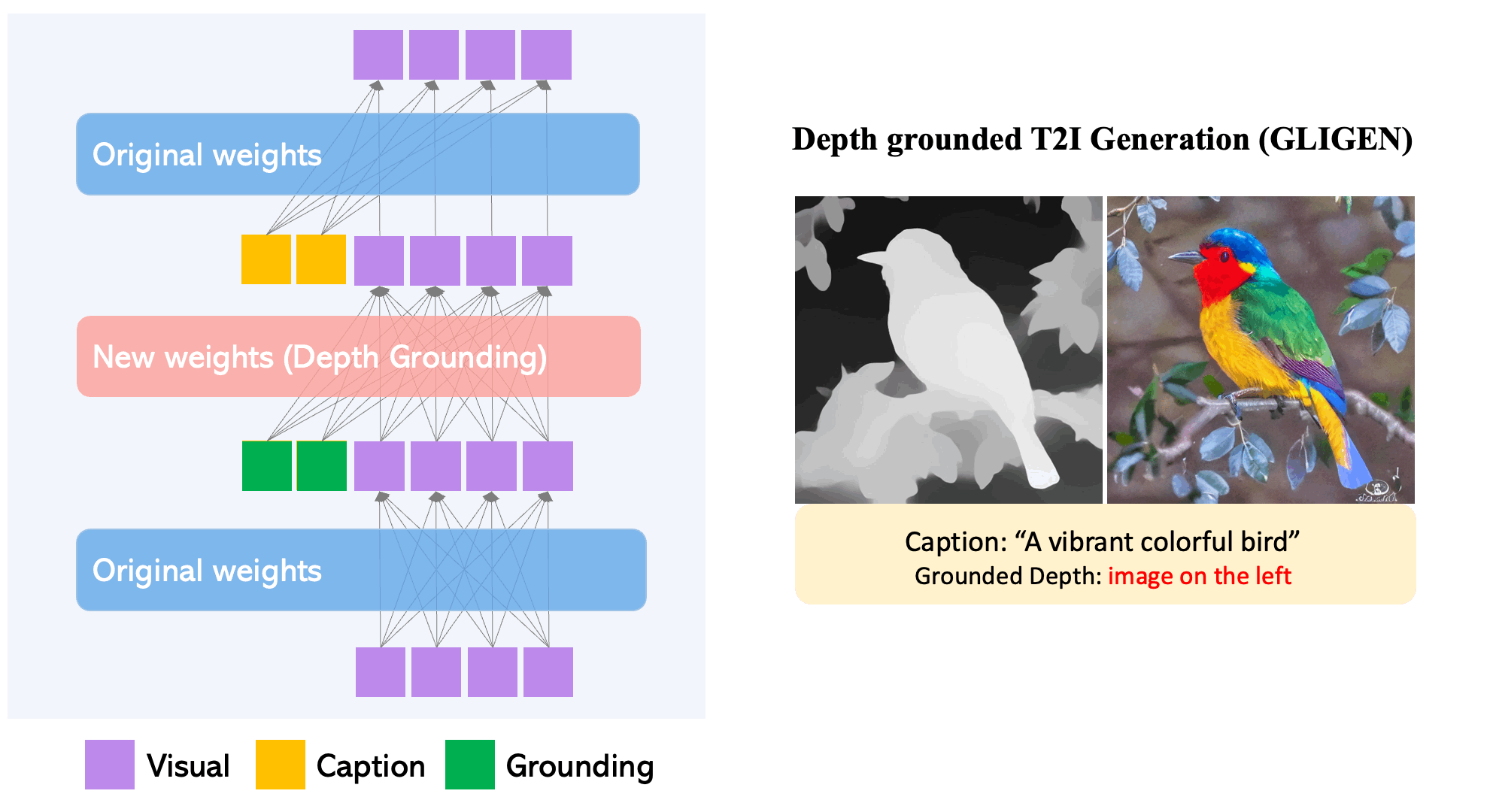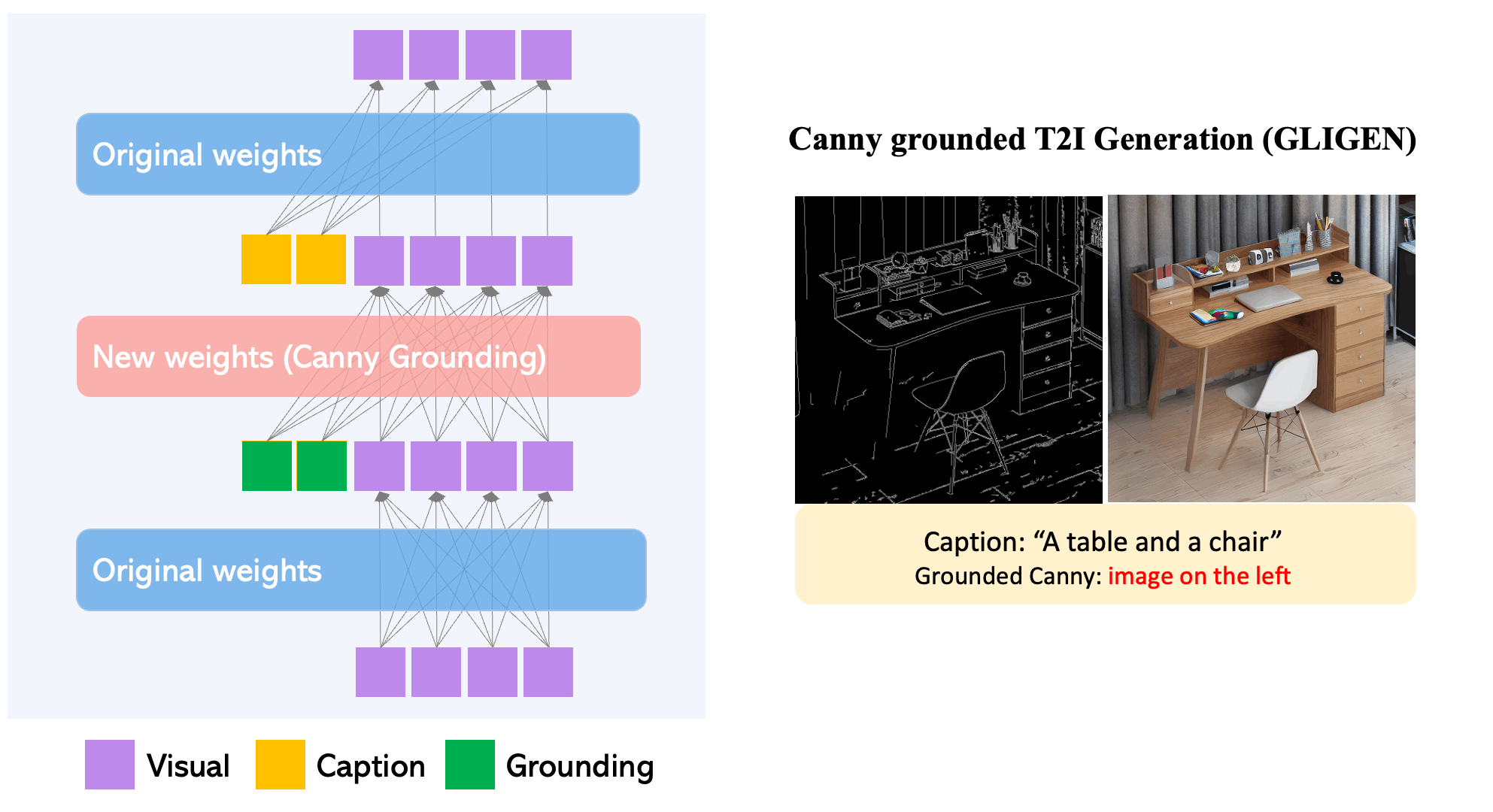
Figure 1. GLIGEN enables versatile grounding capabilities for a frozen text-to-image generation model.
Large-scale text-to-image diffusion models have made amazing advances. However, the status quo is to use text input alone, which can impede controllability. In this work, we propose GLIGEN, Grounded-Language-to-Image Generation, a novel approach that builds upon and extends the functionality of existing pre-trained text-to-image diffusion models by enabling them to also be conditioned on grounding inputs. To preserve the vast concept knowledge of the pre-trained model, we freeze all of its weights and inject the grounding information into new trainable layers via a gated mechanism. Our model achieves open-world grounded text2img generation with caption and bounding box condition inputs, and the grounding ability generalizes well to novel spatial configuration and concepts. GLIGEN’s zero-shot performance on COCO and LVIS outperforms that of existing supervised layout-to-image baselines by a large margin.
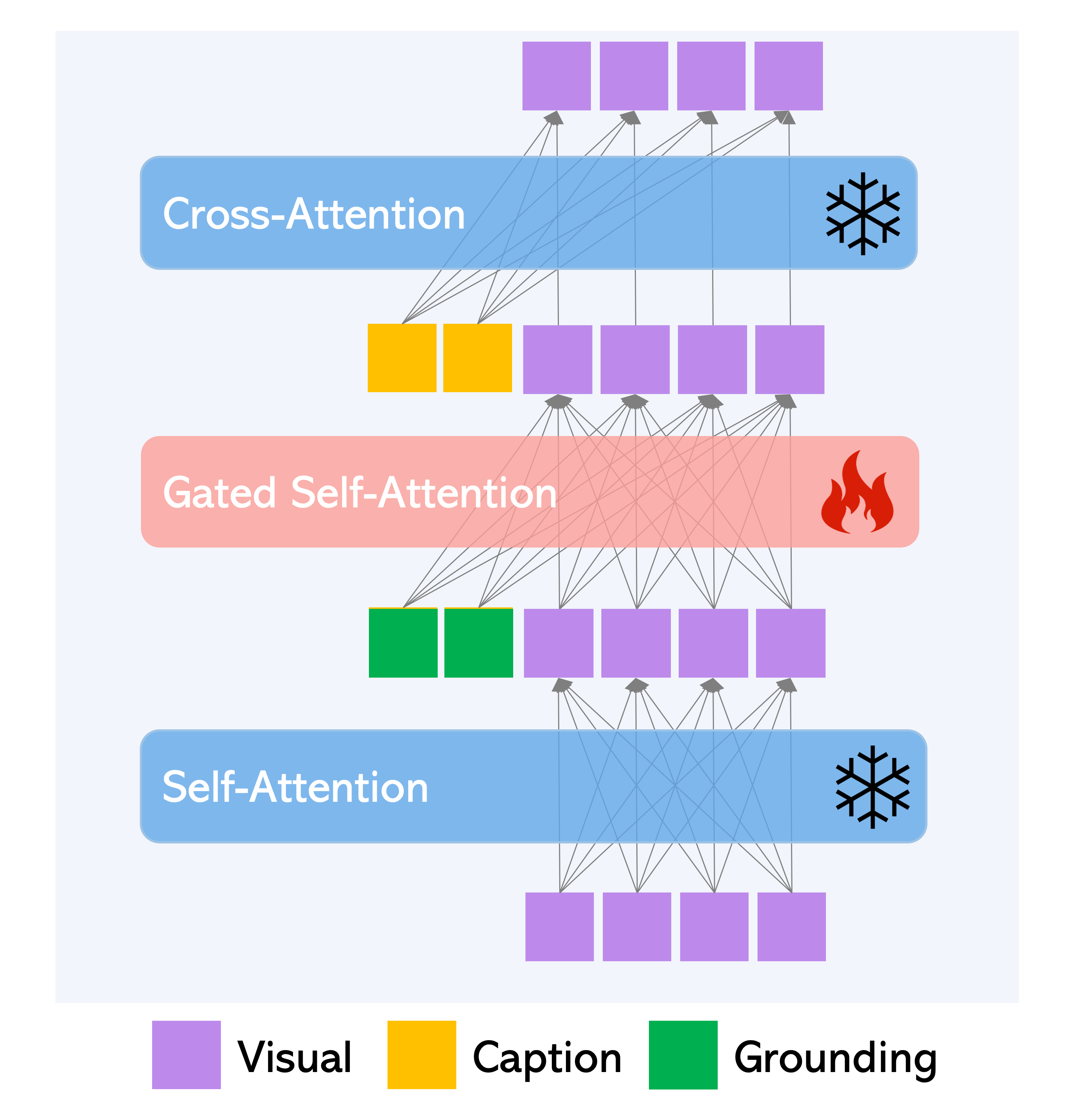
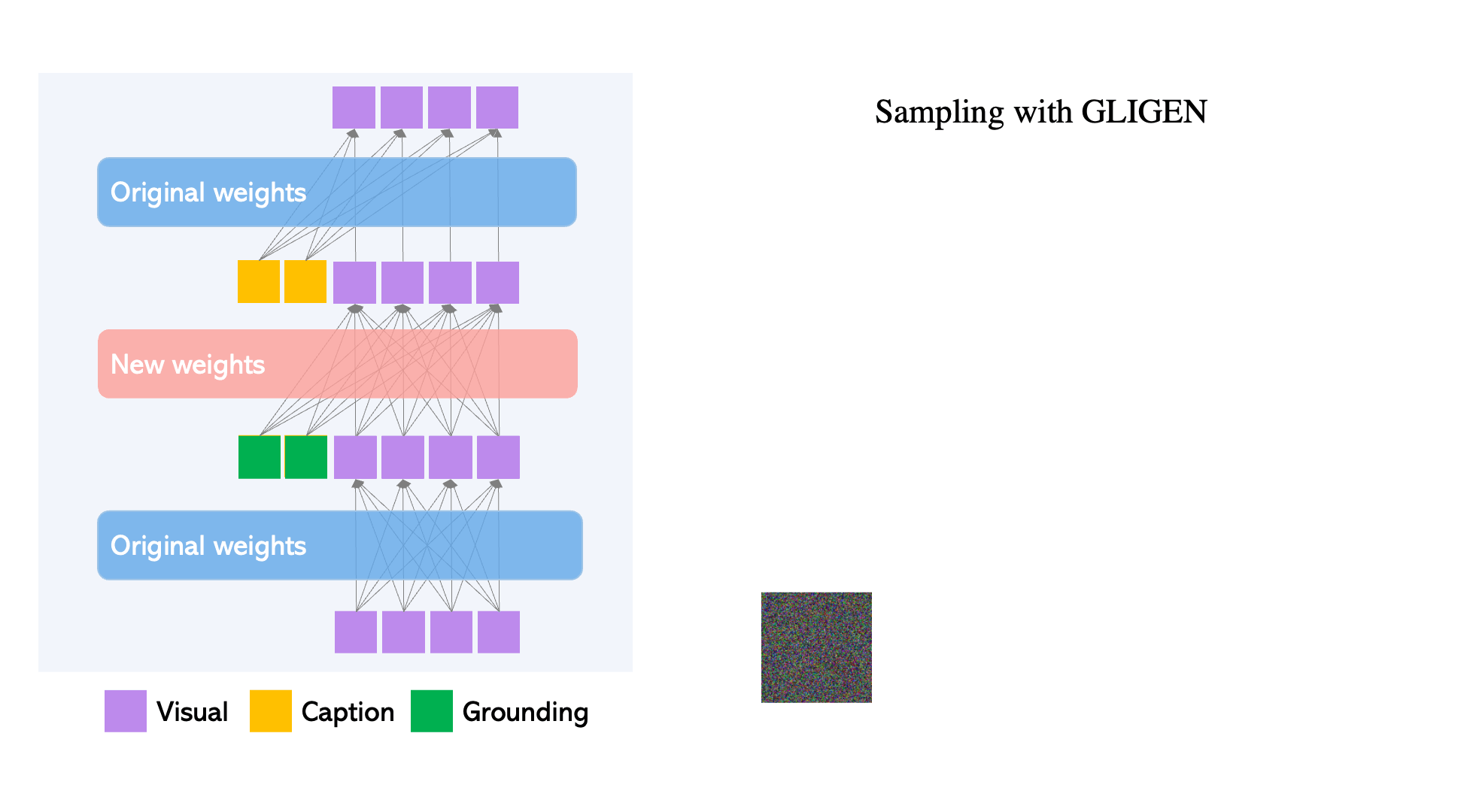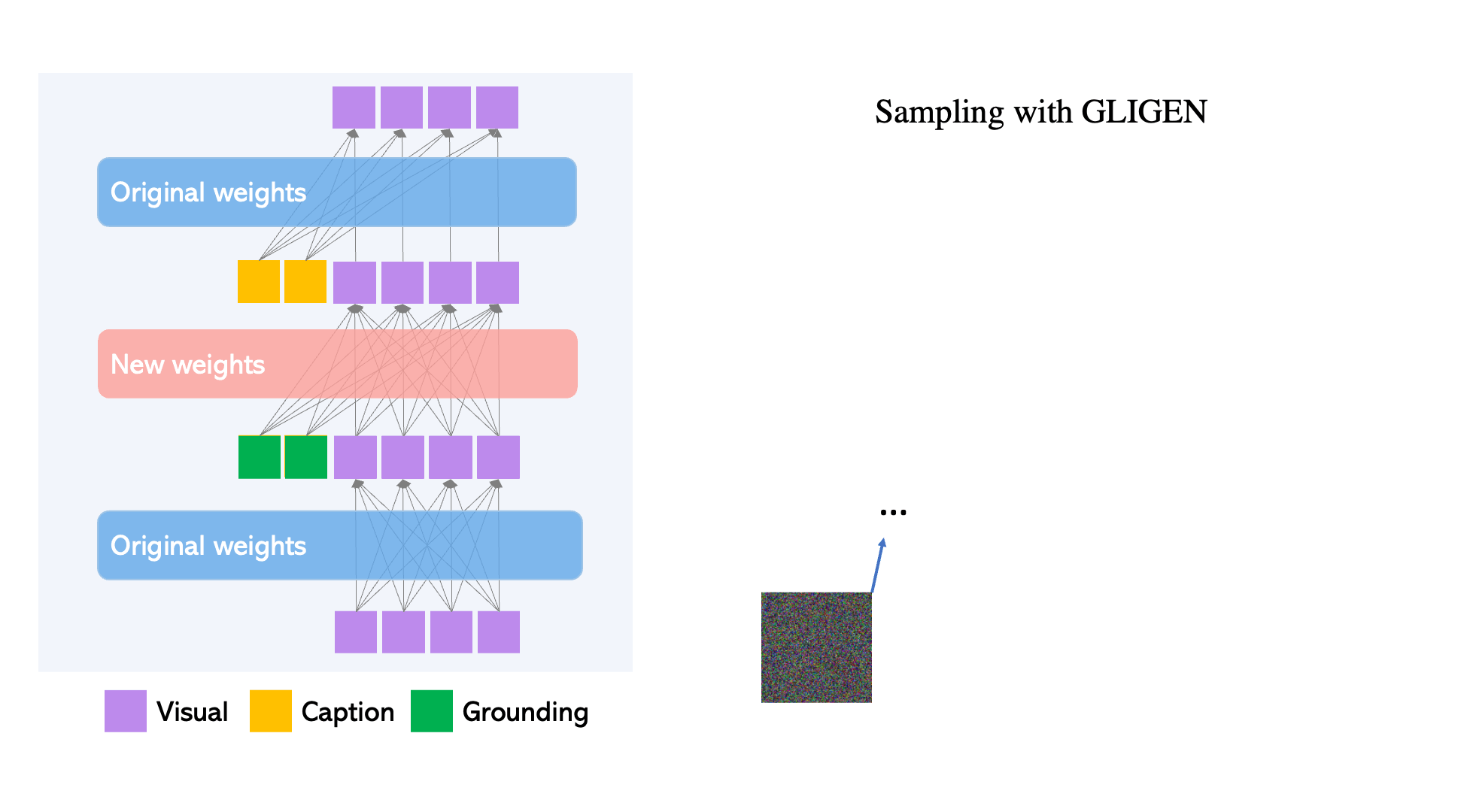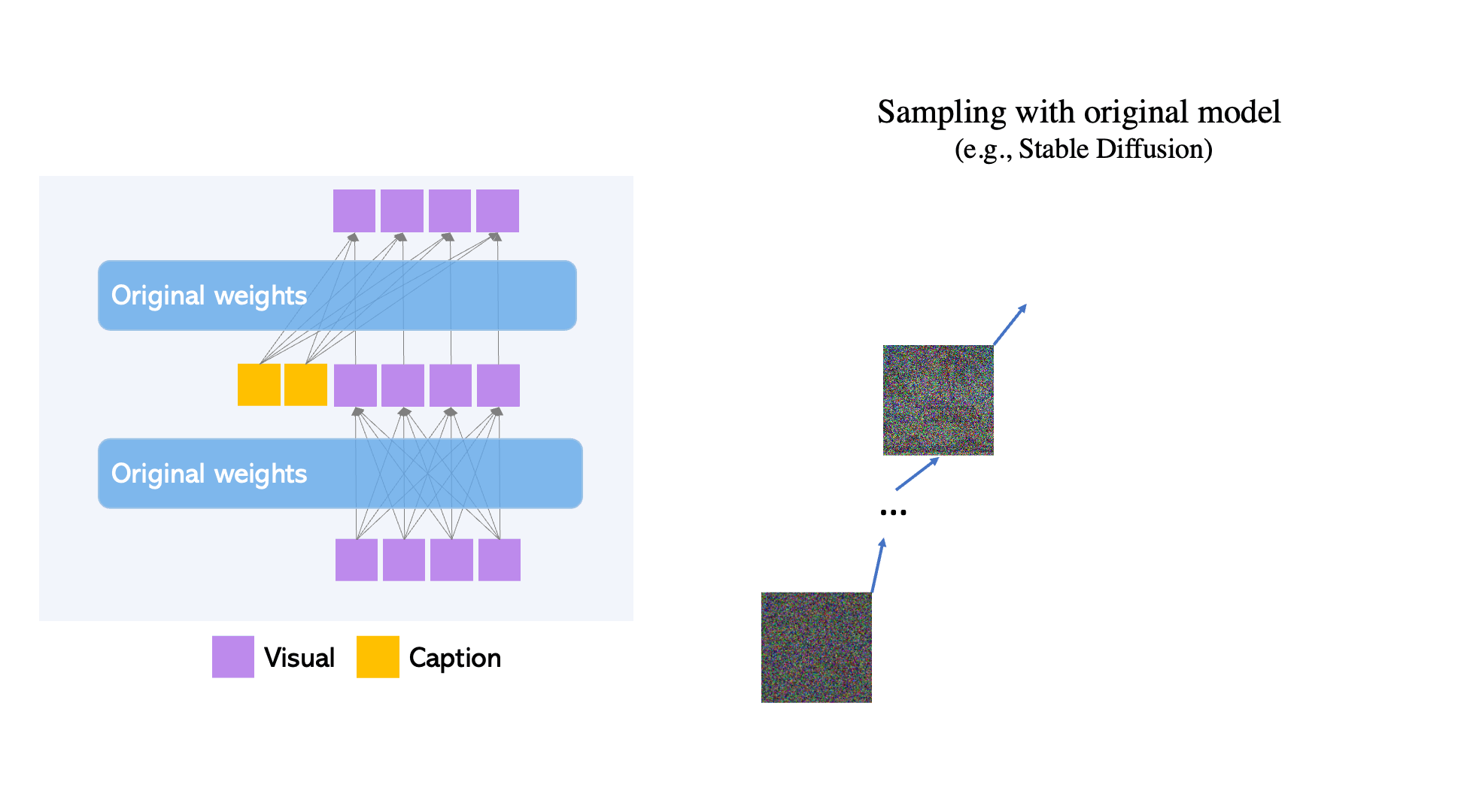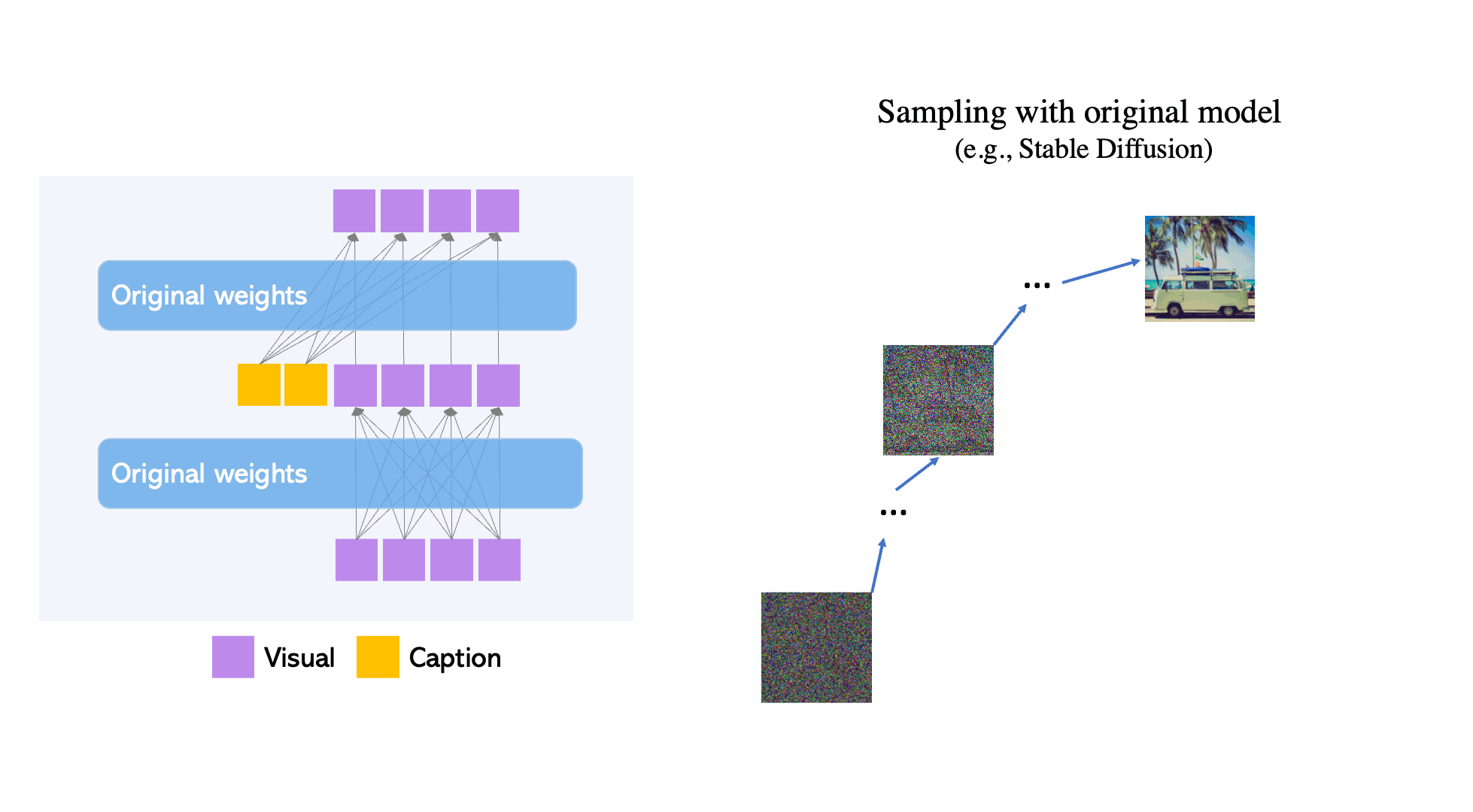
Figure 2. Gated Self-Attention is used to fuse new grounding tokens.

By exploiting knowledge of pretrained text2img model, GLIGEN can generate varieties of objects in given locations, it also supports varies of styles.

Compared with existing text2img models such as DALLE1 and DALLE2, GLIGEN enables the new capability to allow grounding instruction. The text prompt and DALLE generated images are from OpenAI Blog.

By explicitly specifying object size and location, GLIGEN can generate spatially counterfactual results which are difficult to release through text2img model (e.g., Stable Diffusion).

GLIGEN can also ground on reference images. Top row indicates reference images can provide more fine-grained details beyond text description such as style and shape or car. The second row shows reference image can also be used as style image in which case we find ground it into corner or edge of an image is sufficient.

Like other diffusion models, GLIGEN can also perform grounded image inpaint, which can generate objects tightly following provided bounding boxes.

GLIGEN results on canny maps.

GLIGEN results on depth maps.

GLIGEN results on normal maps.

GLIGEN results on semantic maps.

GLIGEN results on hed maps.
We have strict terms and conditions for using the model checkpoints and the demo; it is restricted to uses that follow the license agreement of Latent Diffusion Model and Stable Diffusion.
It is important to note that our model GLIGEN is designed for open-world grounded text-to-image generation with caption and various condition inputs (e.g. bounding box). However, we also recognize the importance of responsible AI considerations and the need to clearly communicate the capabilities and limitations of our research. While the grounding ability generalizes well to novel spatial configuration and concepts, our model may not perform well in scenarios that are out of scope or beyond the intended use case. We strongly discourage the misuse of our model in scenarios, where our technology could be used to generate misleading or malicious images. We also acknowledge the potential biases that may be present in the data used to train our model, and the need for ongoing evaluation and improvement to address these concerns. To ensure transparency and accountability, we have included a model card that describes the intended use cases, limitations, and potential biases of our model. We encourage users to refer to this model card and exercise caution when applying our technology in new contexts. We hope that our work will inspire further research and discussion on the ethical implications of AI and the importance of transparency and accountability in the development of new technologies..
@article{li2023gligen,
author = {Li, Yuheng and Liu, Haotian and Wu, Qingyang and Mu, Fangzhou and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan and Lee, Yong Jae},
title = {GLIGEN: Open-Set Grounded Text-to-Image Generation},
publisher = {arXiv:2301.07093},
year = {2023},
}
This website is adapted from Nerfies and X-Decoder, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

